
soft IT life
제 52회 SQLD 시험 대비 요약정리(2024년 변경된 출제 범위 적용) 본문
변경된 출제 범위
2024년 제 52회부터 SQLD 시험 범위가 변경되었다.
변경된 시험 범위에 대한 자세한 내용은 아래 링크 참조
데이터자격시험
www.dataq.or.kr
- 변경된 범위


- 자세한 출제 범위

- 배점 및 문항수
기존에는 단답식 주관식도 존재하였으나 52회부터 모든 문제가 객관식 문항으로 변경되었음

중요한 키워드 중심으로 요약 정리 !
데이터 모델링의 이해
데이터 모델의 이해
- 모델링 특징
- 추상화 : 다양한 현상을 일정한 양식에 따라 표현
- 단순화 : 복잡한 현상을 쉽게 이해할 수 있게 표현
- 명확화 : 현상에 대한 애매모호함을 제거
- 모델링 관점
- 데이터 관점 : 업무가 어떤 데이터와 관련 있는지, 데이터 간의 관계
- 프로세스 관점 : 실제 업무가 무엇인지, 무엇을 해야하는지를 모델링
- 데이터와 프로세스 상관 관점 : 업무 방법에 따라 데이터가 어떻게 영향 받는지
- 데이터 모델링의 중요성 : 파급효과, 복잡한 정보 요구 사항의 간결한 표현, 데이터 품질
- 데이터 모델링의 유의점 : 중복, 비유연성, 비일관성
- 추상화 수준에 따른 단계
- 개념적 데이터모델링
- 추상화 수준 가장 높음, 전사적
- 핵심 엔터티와 그들 간의 관계 발견하고 그것을 표현하기 위해 엔터티-관계 다이어그램을 생성하는 것
- 논리적 데이터모델링
- 업무에 대해 속성, 관계 등을 표현. 가장 핵심
- 데이터 모델링이 최종적으로 완료된 상태. 즉 물리적인 스키마 설계 직전 단계
- 정규화
- 물리적 데이터모델링
- 실제 DB에 이식 하도록 성능, 저장 등 고려
- 개념적 데이터모델링
- 데이터 모델링의 고려사항
- 독립성
- 독립성이 확보된 모델 -> 업무 변화에 능동적 대응 가능, 관리 유지보수 비용 절감
- 독립성을 확보하기 위해 중복된 데이터를 제거 해야 한다 -> 정규화
- 독립성
- 데이터 독립성을 위한 데이터베이스 3단계 구조(3층 스키마)
- 외부 단계 : 개개인 사용자 관점의 개인적 DB, 응용프로그램이 접근하는 데이터베이스 정의
- 개념적 단계 : 모든 사용자 관점을 통합한 조직 전체의 DB
- 내부 단계 : 물리적 장치에서 데이터가 실제적으로 저장되는 방법 표현
- 독립성
- 논리적 독립성 : 개념 스키마가 변경되어도 외부 스키마는 영향 받지 않도록 함
- 물리적 독립성 : 내부 스키마가 변경되어도 외부, 개념 스키마는 영향 받지 않도록 함
- 사상(Mapping)
- 외부적-개념적 사상(논리적 사상) : 외부적 뷰와 개념적 뷰의 상호 관련성
- 개념적-내부적 사상(물리적 사상) : 개념적 뷰와 저장된 DB의 상호 관련성
- 데이터 모델링의 세 가지 요소
- Things(어떤 것), Attribute(속성), Relationship(관계)
- ERD 표기법으로 모델링 하는 방법
- ERD 작업 순서 : 엔터티를 그림 - 엔터티 간 관계를 설정하고 관계명 작성 - 관계의 참여도(관계 차수) 작성 - 관계의 필수여부 작성
- 좋은 데이터 모델의 요소
- 완전성 : 업무에서 필요로 하는 모든 데이터가 데이터 모델에 정의되어야 한다.
- 중복 배제 : 하나의 DB 내에 동일한 사실은 한 번만 기록되어야 한다.
- 업무 규칙 : 업무 규칙을 데이터 모델에 표현해야 한다.
- 데이터 재사용 : 데이터의 독립성 유지
- 의사소통 : 데이터 모델에 업무 규칙, 관계, 속성 등의 형태로 표현되어야 한다.
- 통합성
엔터티
업무에 필요하고 유용한 정보를 저장하고 관리하기 위한 집합적인 것
- 엔터티의 특징
- 명사 형태
- 업무에서 필요로 하는 정보
- 식별 가능성 : 인스턴스를 각각 구분하기 위해 유일한 식별자가 존재해야 함
- 인스턴스의 집합. 2개 이상의 인스턴스가 존재해야 함
- 인스턴스란? 엔터티:회사 - 인스턴스:삼성, LG, SK ...
- 업무 프로세스에 의해 이용되어야 함
- 속성(Attribute)이 존재해야 함 : 주식별자만 존재하고 속성은 없는 경우
- 최소 한 개 이상의 관계를 가져야 한다.
- 분류
- 유무형에 따른 분류
- 유형 엔티티 : 물리적 형태 존재. ex) 사원, 물품, 강사
- 개념 엔티티 : 개념적 정보. ex) 조직, 보험상품
- 사건 엔티티 : 업무 수행함에 따라 발생) ex. 주문, 청구
- 발생시점에 따른 분류
- 기본 엔티티 : 다른 엔티티로부터 주식별자를 상속받지 않고 자신의 고유한 주식별자를 가짐. 독립적으로 생성
ex) 사원, 부서, 상품 - 중심 엔티티 : 중심 엔티티로부터 발생되며, 다른 엔티티와 관계를 통해 행위 엔티티를 생성함. ex) 사고, 청구, 주문, 매출
- 행위 엔티티 : 두 개 이상의 부모엔티티로부터 발생. 내용이 자주 바뀜 ex) 주문목록, 사원변경이력
- 기본 엔티티 : 다른 엔티티로부터 주식별자를 상속받지 않고 자신의 고유한 주식별자를 가짐. 독립적으로 생성
- 유무형에 따른 분류
속성
업무에서 필요로 하는 엔티티에서 관리할 더이상 분리되지 않는 최소의 데이터 단위
- 한 개의 엔터티는 두 개 이상의 인스턴스 집합이다.
- 한 개의 엔터티(or 인스턴스)는 두 개 이상의 속성을 갖는다.
- 한 개의 속성은 한 개의 속성값만을 갖는다.
- 주식별자에게 함수적으로 종속된다.
- 분해 여부에 따른 분류
- 단일 속성 : 하나의 의미로 구성
- 복합 속성 : 여러개의 의미로 구성 ex) 주소(창원시 성산구 신월동...)
- 다중값 속성 : 여러개의 값으로 구성 ex) 상품리스트
- 특성에 따른 분류
- 기본속성 : 업무로부터 추출한 모든 속성 ex) 제품이름, 제조년원
- 설계속성 : 업무상 필요한 데이터 이외에 모델링이나 규칙을 위해 정의하는 속성 ex) 상품코드
- 파생속성 : 다른 속성에 영향을 받아 발생하는 속성 ex) 계산값
- 도메인 ?
- 속성이 가질 수 있는 값의 범위
관계
엔티티의 인스턴스 사이의 논리적인 연관성
- 관계의 분류
- '부서에 사원이 소속된다' -> 존재에 의한 관계
- '고객이 상품을 주문한다' -> 행위에 의한 관계
- *Association(연관관계) : 존재에 의한 관계, Dependency(의존관계) :행위에 의한 관계
- 관계의 표기법
- 관계명 : 관계의 이름. 엔티티가 관계에 참여하는 형태 ex) 포함한다. 소속된다.
- 관계차수 : 1:1, 1:M, M:N
- 관계선택사항 : 필수관계, 선택관계
- 서술해보기
- 부서:사원=1:M -> 각 부서는 여러 사원이 때때로 소속된다 / 각각의 사원은 하나의 부서에 항상 속한다
식별자
Identifier, 하나의 엔티티에 구성된 여러 개의 속성중에 엔티티를 대표할 수 있는 속성을 의미
하나의 엔티티는 반드시 하나의 유일한 식별자가 존재해야 함
- 주식별자(기본키, PK)의 특징
- 대표성
- 유일성 : 엔터티의 인스턴스를 유일하게 식별 함
- 최소성 : 속성의 수는 최소여야 함(1 개)
- 불변성
- 존재성 : 반드시 값이 존재해야함. Null 안 됨
- cf) 키의 종류
- 기본키
- 후보키 : 유일성과 최소성 만족
- 슈퍼키 : 유일성 만족
- 대체키 : 후보키중 기본키를 선정하고 남은 키
- 외래키 : 타 테이블의 기본키를 가리키는 참조 무결성 확인용 키
- 식별자 분류
- 대표성 여부에 따른 분류
- 주식별자 : 엔티티 내에서 각 데이터를 구분할 수 있는 구분자이며, 타 엔티티와 참조 관계 연결 가능
(사원 - 사번(PK), 부서번호(FK)) - 보조식별자 : 엔티티 내에서 각 데이터를 구분할 수 있는 구분자지만, 대표성을 갖지 못해 참조 관계 연결 불가
(사원 - 사번(PK), 주민등록번호)
- 주식별자 : 엔티티 내에서 각 데이터를 구분할 수 있는 구분자이며, 타 엔티티와 참조 관계 연결 가능
- 스스로 생성 여부
- 내부식별자
- 외부식별자
- 속성 수
- 단일식별자 : 하나의 속성으로 구성
- 복합식별자 : 둘 이상의 속성으로 구성
- 대체 여부
- 본질식별자 : 업무에 의해 만들어짐
- 인조식별자 : 업무와 무관하지만 인위적으로 만듦
- 대표성 여부에 따른 분류
- 식별자 관계 : 부모 엔티티의 주식별자(PK)가 자식 엔티티의 주식별자(FK)로 상속될 때
- 비식별자 관계 : 부모 엔티티로부터 속성을 받았지만 자식 엔티티의 주식별자로 사용되지 않고 속성으로만 사용될 때
- 식별자 관계와 비식별자 관계 모델링
- 기본적으로 식별자관계로 설정하되 아래와 같은 조건에 해당하는 경우 비식별자관계로 조정할 것
- 관계 분석 -> 관계의 강약 분석 -> 약한 관계 -> 비식별자 관계
- 관계 분석 -> 관계의 강약 분석 -> 자식테이블 독립 PK 필요 -> 독립 PK 구성 -> 비식별자 관계
- 관계 분석 -> 관계의 강약 분석 -> 자식테이블 독립 PK 필요 -> SQL 복잡도 증가, 개발 생산성 저하 -> 비식별자 관계
- 기본적으로 식별자관계로 설정하되 아래와 같은 조건에 해당하는 경우 비식별자관계로 조정할 것
정규화
데이터의 일관성, 데이터의 중복 최소화, 데이터의 유연성 최대화, 데이터 독립성 확보 등을 위한 방법
비즈니스 변화가 발생해도 데이터 모델의 변경을 최소화할 수 있음
- 제 1 정규형 : 모든 속성은 반드시 하나의 값을 가진다. 속성의 원자성
- 기본키를 설정한다.
- 제 2 정규형 : 엔티티의 일반 속성은 주식별자 전체에 종속적이어야 한다.(부분 함수 종속성 제거)
- 주문상세 엔티티(주문과 상품의 매핑테이블)
- 주문번호(주식별자)
- 상품번호(주식별자)
- 상품명(속성)
- 이 엔티티를 보면 상품명은 상품번호에만 종속된다(상품번호:결정자, 상품명:종속자) 주문상세 엔티티의 주식별자는 주문번호와 상품번호지만 엔티티의 속성이 부분적으로만 종속적인 것이다. => '부분 종속' -> 제 2정규형 위반
- 이를 해결하기 위해 주문상세 엔티티는 주분번호, 상품번호만을 가지게 수정하고, 상품번호를 주식별자로, 상품명을 속성으로 가지는 '상품' 엔티티를 새로 만든다.
- 주문상세 엔티티(주문과 상품의 매핑테이블)
- 제 3 정규형 : 엔티티의 일반 속성 간에는 서로 종속적이지 않다.(이행 함수 종속성 제거)
- 주문 엔티티
- 주문번호(주식별자)
- 고객번호(속성)
- 고객명(속성)
- 고객번호는 주문번호에 종속적이고, 고객명은 고객번호에 종속적이다. -> '이행적 종속'
- 고객명이 일반 속성에 종속적이다. -> 제 3정규형 위반
- 주문 엔티티
- 정규화는 무조건적이지는 않다. 정규화가 많으면 조인이 많아지고 이는 성능저하를 일으킬 수 있다.
반정규화
정규화가 데이터의 중복을 최소화 하는거라면 반정규화는 성능을 위해 데이터 중복을 허용하는 것
- 수행하는 경우 ?
- 수행 속도가 느린 경우
- 다량의 범위를 자주 처리
- 특정 범위의 데이터만 자주 처리
- 요약/집계 정보가 자주 요구
- 반정규화 기법
- 계산된 컬럼 미리 추가
- 배치 프로그램으로 집계/요약 정보를 미리 계산하고 결과를 컬럼에 추가한다.
- 테이블 수직 분할 : 컬럼을 기준으로 테이블 분할
- 테이블 수평 분할 : 값을 기준으로 테이블 분할
- 파티션 ? : 파티션을 이용해 테이블을 분할할 수 있다. 논리적으로는 하나의 테이블이지만 여러 개의 데이터 파일에 분산되어 저장됨.
- Range Partition : 값의 범위를 기준으로 분할
- List Partition : 특정 값을 지정하여 분할
- Hash Partition : 해시 함수 이용
- Composit Partition : 범위와 해시를 복합적으로 사용
- 파티션의 장점 ?
- 데이터 조회 시 액세스 범위가 줄기 때문에 성능 향상
- Input Output 성능 향상
- 각 파티션 독립적으로 백업 및 복구 가능
- 테이블 병합
- 슈퍼 타입과 서브 타입 관계가 발생하면 테이블을 통합하여 성능 향상 시킴
- 고객 엔터티는 개인고객, 법인고객으로 분류 됨 -> 고객 엔터티 = 슈퍼 타입 / 고객종류 = 서브 타입
- 계산된 컬럼 미리 추가
- 반정규화가 무조건 성능을 향상시키는 것은 NO. -> 조회성능은 높아질지라도, Insert, Update, Delete는 저하될 수 있음(데이터 모델의 유연성 낮아짐).
반정규화를 통해 하나의 엔티티에 여러 속성이 존재하면 업무 프로세스에 의해 당장 insert되지 않고 이후에 insert되는 속성도 존재하게 된다. 이는 이후에 Update 쿼리를 사용해야한다는 것이다. 결국 쿼리를 두 번 사용해야하는 것임.
관계와 조인의 이해
관계를 맺는 것은 부모 식별자를 자식이 상속하는 것
- 자식이 상속받은 식별자를 본인의 식별자에 포함하면 식별관계
- 자식이 상속받은 식별자를 본인의 일반 속성에 포함하면 비식별관계
이런 관계는 상속된 데이터를 이용해 엔티티간에 매핑이 가능하다.
- 계층형 데이터 모델 (Self Join)
- ex) 사원테이블 -> 사원번호, 이름, 매니저 사원번호 = 사원번호와 매니저 사원번호 간에 상속 관계가 발생
- 상호 배타적 관계(Exclusive-OR)
모델이 표현하는 트랜젝션의 이해
데이터 베이스의 논리적 연산 단위 ex) 계좌 송금 = 잔액 차감 -> 입금이 하나의 업무 단위로 묶여서 처리 되어야 한다.
데이터 모델링에서의 트랜잭션이란 ?
- 주문, 주문상세 엔티티는 함께 발생하는지 독립적으로 발생하는지 ?
주문을 함으로써 주문상세도 필수적으로 데이터가 입력되어야 한다. -> 주문 insert, 주문상세 insert가 하나의 commit으로 함께 진행되어야 하는 것이다. - 태생적으로 함께 발생, 처리되는 데이터는 하나의 트랜젝션으로 처리 된다.
Null 속성의 이해
Null = 아직 정의되지 않은 미지의 값 or 현재 데이터를 입력하지 못하는 경우 (공백 or 숫자 0 의 뜻이 아니다 !)
1. Null 값의 연산(+,-,/,*)은 언제나 Null
- Null은 연산이 불가능하다.
- Null의 연산은 유일하게 IS NULL, IS NOT NULL만 가능하다.
- NVL(a, b) = a가 Null일 경우 b를 반환
2. 집계함수는 Null 값을 제외하고 처리함
- 집계함수란? Aggregate Function(Column Function)
- 행그룹에 따라 결과 단일행을 반환한다.
- 모든 Data
- count(column) : 개수
- Count(*) : null 상관 없이 모든 행을 계산 한다.
- Count(column) : null 제외하고 계산 한다.
- max(column) : 최대값
- min(column) : 최소값
- count(column) : 개수
- 숫자 Data
- sum(column) : 합계
- avg(column) : 평균
- 위 집계함수들은 null 속성은 제외하고 계산한다.
- cf) 집계함수의 사용은 Select, Having 절에서만 가능하다.
ex)
| 주문취소금액 |
| 20,000 |
| null |
| 10,000 |
| 10,000 |
Select SUM(주문취소금액)/count(*) col1
Select AVG(주문취소금액) col2
col1 = 40,000/4
col2 = 40,000/3
3. Null 관련 함수
- NVL(a,0) : a가 null이면 0을 반환
- NVL2(a,1,0): a가 null이 아니면 1을, null이면 0을 반환
- NULLIF(a,b) : a와 b가 일치하면 null, 일치하지 않으면 a를 반환
- COALESCE(a,b,c,d...) : Null이 아닌 최초의 인자 값을 반환
본질식별자 vs 인조식별자
식별자란? 엔티티는 반드시 데이터를 식별할 수 있는 속성이 존재 해야함. 이를 식별자라 한다.
대체 여부에 따라 본질식별자(업무에 의해 생성)/인조식별자(업무와 무관한 UUDI 등)로 분류
외부식별자(스스로 생성하지 않은 식별자)의 문제점
- 중복 데이터
- 실수로 값이 두번 insert되면 중복 데이터를 막을 수 있을까? 인조식별자(Index)가 식별자이기 때문에 값이 두번 insert되며 중복 데이터가 발생된다.
- 불필요한 인덱스 생성
SQL 기본
관계형 데이터베이스
관계형 데이터베이스는 테이블을 기본 단위로 저장된다.
데이터베이스의 종류 : 계층형, 네트워크형, 관계형
관계형 데이터베이스는 관계를 이용해 집합 연산, 관계 연산 등이 가능하다.
집합 연산
- 합집합(Union) : 중복된 행은 한 번만 조회됨
- 차집합(Difference) : 본래것에만 존재하며, 다른것에 존재하지 않는 것 조회
- 교집합(Intersection) : 두 개 간에 공통된 것 조회
- 곱집합(Cartesian product) : 각에 존재하는 모든 데이터를 조합(곱한만큼 레코드 나옴)
관계 연산
- 선택연산(Selection) : 조건에 맞는 행 조회
- 투영연산(Projection) : 조건에 맞는 속성 조회
- 결합연산(Join) : 여러 테이블 간에 공통된 속성을 사용해서 새로운 테이블 만들어 냄
- 나누기연산(Division)
SQL이란? (Structured Query Language)
관계형 데이터베이스에 대해서 데이터의 구조를 정의, 데이터조작, 데이터제어 등을 할 수 있는 절차형+비절차형 언어
- DDL(Data Definition Language) : CREAT, ALTER, DROP, RENAME, TRUNCATE
- DML(Data Manipulation Language) : INSERT, SELECT, DELETE, UPDATE
- DCL(Data Control Language) : 사용자에게 권한 부여 혹은 회수 GRANT, REVOKE
- TCL(Transaction Control Language) : 트랜젝션 제어 COMMIT, ROLLBACK, SAVEPOINT
- SQL 실행 순서 : 파싱 - 실행 - 인출
트랜젝션
- 데이터베이스의 작업을 처리하는 단위
- 특성
- 원자성 : 연산의 전부가 실행되거나 전혀 실행되지 않아야 한다(ALL or Notion)
- 일관성 : 트랜젝션 실행 결과로 데이터 베이스 상태가 모순되지 않아야한다. 실행 후에도 일관성 유지
- 고립성 : 트랜젝션 실행 중에 다른 트랜젝션은 접근할 수 없음
- 영속성 : 실행을 성공적으로 완료하면 그 결과는 영구적 보장
자주 쓰이는 데이터 유형
- CHARACTER(s) (Oracle=CHAR)
- 고정 길이 문자열 정보
- 기본 길이=1바이트, 최대 길이=Oracle 2000바이트 / SQLServer 8000바이트
- 지정 길이보다 할당된 값의 길이가 더 작을 경우 길이 차이만큼 공간으로 채워짐
- VARCHAR(s) (Oracle=VARCHAR2 / SQLServer=VARCHAR)
- 최소 길이=1바이트, 최대 길이=Oracle 4000바이트 / SQLServer 8000바이트
- 지정 길이만큼 최대를 갖지만 가변 길이로 조정 되기 때문에 할당된 값에 따라 바이트가 적용됨
- NUMERIC (Oracle=NUMBER / SQLServer=INT,DOUBLE,FLOAT,BIGINT,INTEGER...)
- 전체 자리 수 지정, 소수 자리 수 지정 -> NUMBER(6,2) : 총 6자리, 소수자리는 2자리(정수는 4자리)
- DATETIME (Oracle=DATE / SQLServer=DATETIME)
- Oracle은 1초 단위, SQLServer는 3.3ms(millisecond) 단위 관리
SELECT 문
Distinct : 중복된 데이터가 있는 경우 1건으로 처리해서 조회
Select Distinct column
From
Where
Alias 부여 (별칭)
- 컬럼명 바로 뒤에 옴
- alias가 공백, 특수문자를 포함할 경우, 대소문자 구분 필요한 경우 -> "" 사용
Select column AS "선수 명"
From
Where
산술 연산자
- NUMBER, DATE 자료형에 적용 됨
- (),*,/,+,-
Select column+column AS "합"
From
Where
합성 연산자
- 문자와 문자를 연결
- Concat(string1, string2) or || or 문자+문자
Select name || '선수, ' || height || 'cm' AS 체격정보
From
출력 결과
체격정보
김양수 선수, 190cm
함수
내장 함수 - 단일행 함수
단일행 함수는 처리하는 데이터의 형식에 따라 문자형, 숫자형, 날짜형, 변환형 등으로 나뉨
- 문자형 : Lower, Upper, Concat, Len ...
- 숫자형 : Abs, Sign, Mod, Ceil, Floor, Round
- 날짜형 : Sysdate, to_number(to_char(d,'yyyy'))
- 변환형 : to_char, to_number
- Null 관련 : isnull, nvl, nullif, coalesce
- 특징
- Select, Where, Order by 절에서 사용 가능
- 단 하나의 결과만 리턴 함
문자형 함수
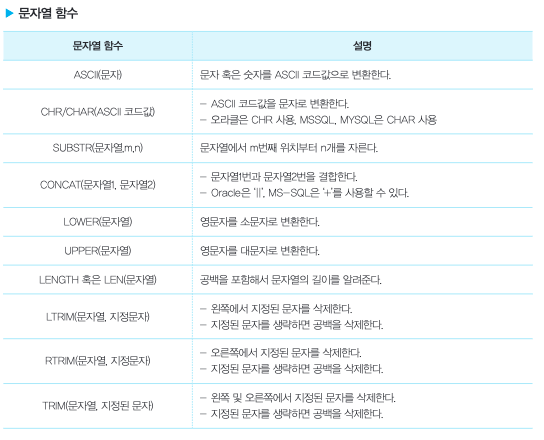
숫자형 함수
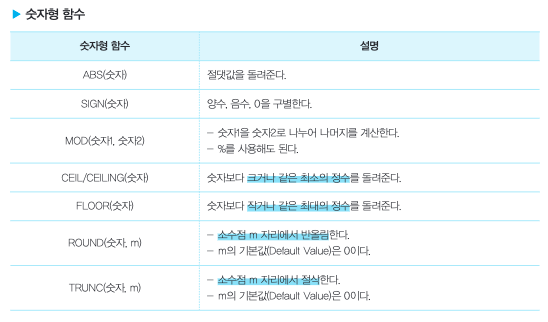
날짜형 함수

형변환 함수

CASE
만약 else를 명시하지 않으면 null 출력
Select Case
When column = 10 then 'a'
When column = 20 then 'b'
Else 'c'
End
From
DECODE
column이 1000이면 a를 출력, 맞지 않으면 b를 출력
Select Decode (column, 1000, a, b)
From
Null 함수
Null의 연산은 불가능 -> 결과값이 무조건 null 출력됨 ! 원하는 값을 제대로 계산할 수 없음. -> NVL() 함수 등을 사용
Where 절에서 IS NULL / IS NOT NULL 계산은 가능
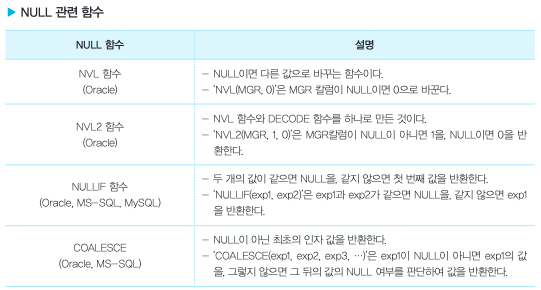
*조건에 일치하는 데이터가 하나도 없는 집합 = 공집합 (Null데이터가 아님 !)
WHERE 절
비교 연산자(+부정비교연산자)
- 문자열 비교는 ' ' 로 감싸주어야 함
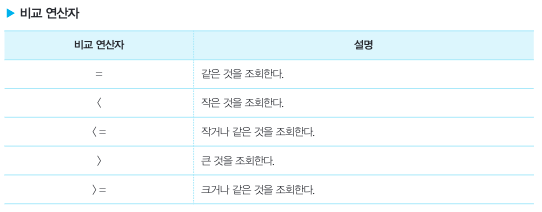

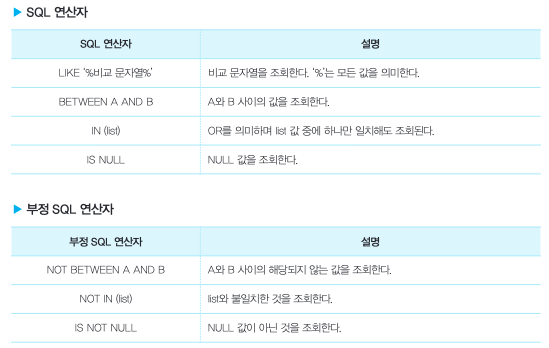
SQL 연산자(+부정SQL연산자)
논리 연산자

*연산자의 우선순위
- ()
- 비교 연산자, SQL 연산자
- NOT 연산자
- AND
- OR
GROUP BY, HAVING 절
특징
- Group By 절을 통해 소그룹별 기준을 정한 후, Select 절에서 집계함수를 사용한다.
- 집계함수의 통계 정보는 Null 제외 하고 계산
- Group By에서는 Alias 사용 불가 ! (order by는 가능)
- 집계 함수는 Where 절에서는 불가하다 !
- Where절에서는 그룹화 하기전에 행들을 미리 제거한다.
집계 함수
- 여러 행의 그룹이 모여 단 하나의 결과를 돌려주는 함수
- Select, Having, Order by에서 사용 가능
ORDER BY 절
- 조회한 데이터들을 특정 컬럼을 기준으로 정렬
- alias 사용 가능
- 컬럼 순서로도 정렬 가능
- Select 절에 없는 컬럼으로도 정렬이 가능하다.
- Oracle : Null을 가장 큰 값으로 인식 -> 오름차순=가장 마지막, 내림차순=첫 번째
- SQL Server : Null을 가장 작은 값으로 인식 -> 오름차순=첫 번째, 내림차순=가장 마지막
조인
Inner Join : Join의 결과가 true 인 행들만 반환하는 내부 조인
- Equi Join
- PK-FK 관계, 컬럼이 정확히 일치하는 경우 조인 가능. 반드시 이 관계여야만 하는 것은 아니다.


- Non Equi Join
- 두 테이블 간에 논리적인 연관 관계를 가지고 있으나 칼럼이 정확히 일치 하진 않는 경우
Outer Join : Join의 결과가 조건을 만족하지 않는 행들도 함께 반환 할 때 사용되는 조인
- 한 쪽 테이블에만 있는 데이터도 포함 시켜 조회 한다. 기준이 되는 테이블(조인할 데이터가 없는데도 모든 데이터를 표시할 테이블)은 DEPT이다. 이런 경우 기준 테이블의 반대편에 (+) 작성한다.

표준 조인
Inner Join
- Join의 Default는 Inner Join이므로 Inner 키워드는 생략 가능. 아래 세 개의 쿼리는 모두 동일 하다.
Select *
From emp a, dept b
Where b.no = a.no;
Select *
From emp a INNER JOIN dept b
ON b.no = a.no;
Select *
From emp a JOIN dept b
ON b.no = a.no;
Natural Join
- 두 테이블 간에 동일한 이름을 갖는 모든 컬럼에 대해 Equi Join을 수행
- Natural Join이 명시되면, Using 조건절, On 조건절, Where 조건절에서 조인 조건을 정의할 수 없다.
SQL 활용
서브 쿼리
일반적으로 WHERE절에서 사용되는 Select문을 뜻한다.
FROM절에 사용되는 Select문 = Inline View
SELECT절에서 사용되면 Select문 = Scala Subquery
1. 단일 행 서브쿼리
- 서브쿼리 실행 시 반드시 한 행만 조회됨
- 비교연산자(=, <, <=, >, >=. <>) 사용
2. 다중 행 서브쿼리
- 서브쿼리 실행 시 여러 개의 행이 조회됨
- 다중 행 비교 연산자(IN, ANY, ALL, EXISTS) 사용
- 컬럼 IN(select절) : select된 행들 중 일치하는 행(하나라도 ok)
- 컬럼 ALL(select절) : select된 행들 모두가 일치해야 함 -> 비교연산자와 사용 가능
- EXISTS(select절) : select된 행이 단 하나라도 존재하면 true 반환
3.Scala 서브쿼리
- SELECT절에서 사용되는 서브쿼리
- 반드시 한 컬럼, 한 행만을 반환
4. 연관(Correlated) 서브쿼리
- 서브쿼리 내에서 메인쿼리 내의 컬럼을 사용하는 것
- ex) Select xxx From emp a Where a.xx = (select xxx from dept d where d.xx = a.xx)
집합 연산자
그룹 함수
윈도우 함수
Top N 쿼리
계층형 질의와 셀프 조인
PIVOT 절, UNPIVOT 절
정규 표현식
관리 구문
DML
TCL
DDL
DGL
'SQL' 카테고리의 다른 글
| SQLD 대비 오답노트 (0) | 2024.03.04 |
|---|---|
| MySQL 특정 테이블의 레코드를 다른 테이블로 복사하기 (0) | 2024.01.08 |
| 개념정리 - DBMS / SQL(DDL,DML,DCL, DataType) (0) | 2023.08.02 |
